发布时间:2023-06-12 | 阅读:
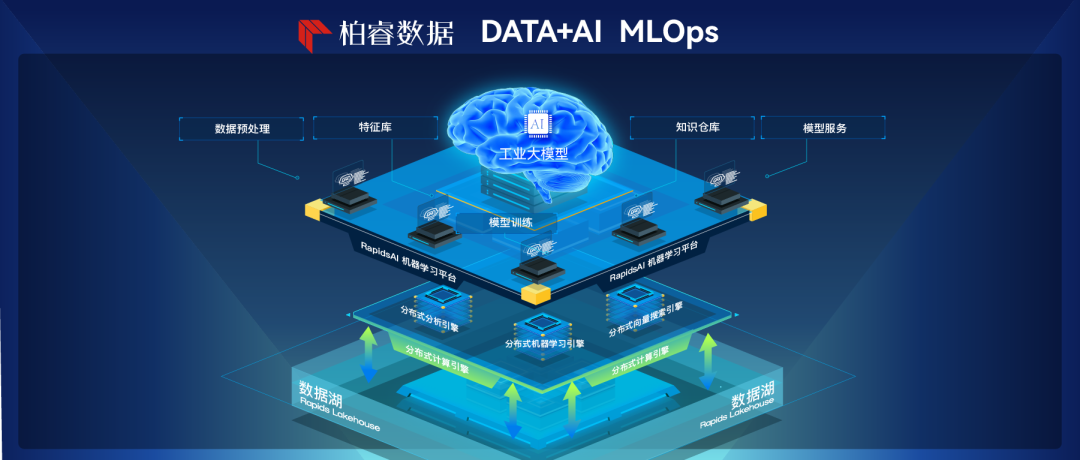

生成式AI大模型在智能对话、内容创作、编程等人机交互场景中大放异彩,各行业企业也在积极构建自己的AI模型,以支撑垂直专业领域的智能化应用,提升企业洞察力,创造业务新价值。 但AI大模型不具备长期记忆能力,在服务垂直专业领域时会存在知识深度和记忆时效性不足的问题,企业构建属于自己的大模型面临挑战。 基于此现状,柏睿数据推出LLMOps平台、向量存储查询引擎两种产品方案,助力企业高效、简单地构建和应用完美适配业务场景的AI大模型。企业不仅能够通过柏睿LLMOps平台在大模型上做垂直领域的模型微调,还可通过向量存储查询引擎,基于企业的自有知识资产构建本地知识问答服务,使得服务更加专业、实时且智慧。
LLMOps本质是人工智能研发运营体系(MLOps)的子类别。柏睿数据智能平台Rapids AI 是一个以数据为中心、以MLOps为方法论的机器学习平台,致力于解决 AI 生产过程中团队协作难、管理乱、交付周期长等问题,最终实现高质量、高效率、可持续的 AI 生产过程。
在大模型时代,柏睿数据在基于Rapids AI的已有MLOps生态链中补充LLMOps的能力,更加关注大语言模型的构建和运行,其能力特点包括:
通过柏睿LLMOps平台,通过柏睿LLMOps提供的优化的基础架构、资源管理能力和精简的开发流程,企业能够在本地训练和微调大模型,确保在模型训练、迭代和部署过程中提高效率和控制能力,从而充分利用大模型实现人工智能赋能业务场景的变革能力。
柏睿LLMOps平台的可视化工作流编排能力,使数据科学家和研究人员能够结合大模型及其他应用,通过prompt工程,快速构建工作链,充分发挥大模型的全部潜力,实现敏捷交付。
与传统MLOps类似,LLMOps也具有数据、模型、代码的统一管理和运维能力。对资产的版本和质量进行持续监控和高效统一管理,并加以风险防控和安全管理等手段,从而实现有效治理。
通过可视化的方式编写Prompt并调试,并自动接入上下文或数据集,只需几分钟即可发布AI应用。同时提供模型API服务,助力企业快速将大模型的能力集成到业务场景应用中,而无需关注复杂的后端架构和部署过程。
通过柏睿LLMOps平台,企业可以简化LLM支持应用程序的开发、部署和维护过程,更高效地部署好用、可靠、精准地AI大模型,加速释放大语言模型(LLM)在垂直应用场景中的全部潜力。
但 LLM 更像是容易失忆的大脑,需要海马体来强化记忆,向量数据库就是支撑LLM长期记忆的“海马体”:基于向量数据库,一方面,LLM 通过浏览专用数据与知识使回答更精准;另一方面,LLM 能回忆自己过往的知识和经验,通过“反思”为用户提供更个性化的服务。
向量数据库作为一种能够存储和处理图片、文字、语音等多种数据类型的系统,通过embedding加工使LLM接触和学习的数据向量化,能够有效地支持多模态数据的存储、索引和查询。向量搜索通过与向量数据库中存储的海量向量进行相似度匹配,找到最符合要求的k个记录,此过程可以助力LLM实现相似文本搜索、文本推荐系统、问题回答和知识检索等功能。
柏睿数据作为一家深耕“Data + AI”技术的公司,一直致力于将AI的能力与数据库结合,面向AI大模型时代推出向量存储查询引擎,支持数据的向量化存储和向量索引。柏睿数据RapidsDB的数据联邦机制能够支持结构化数据和向量数据的存储与查询,且采用全内存分布式架构和大规模并行计算引擎,具备高性能、高可用、弹性扩展等特点,切实解决企业对向量的快速检索需求。
基于柏睿数据的大模型训练运维管理生产线 LLMOps及向量存储查询引擎,结合特定行业或应用的场景,企业可获得匹配自身垂直领域的智能化能力。
通过在具有完全知识产权的全内存分布式数据库RapidsDB中引入LLM,柏睿数据推出了具有自然语言接口的分析型数据库。用户通过自然语言提问,可以从RapidsDB的多张数据表中快速查询结果并返回相应分析报告,进一步降低数据库的使用门槛,真正实现“人人都是数据分析师”。
通常,自然语言转SQL是将数据库中所有表的schema传递给大模型,大模型会根据提问和schema信息生成相应的SQL。但是,如果数据库中存在大量的数据表,则会导致传递给数据的schema信息超出token的限制,从而无法完成自然语言转SQL的任务。
针对该问题,柏睿数据首先将数据库中的schema通过embedding转为向量,并存放于向量数据库;再计算问题和schema 向量的相似度,选择与问题匹配的表信息,将筛选后的schema传递给大模型,从而大大减少了单次prompt的token消耗。这样一方面解决了数据表过多无法生成SQL的问题,一方面减少了token数,降低大模型的使用成本。
同时,为让大模型生成更准确的SQL,柏睿数据也在本地利用LLMOps对大模型进行微调,强化大模型对中文的理解和输出,并通过SQL语料的微调,提高SQL生成的准确率。
在工厂设备全生命周期管理中,各个环节都会采集、汇聚海量结构化和非结构化的数据、实时流数据和历史数据等多种类型的数据,并需要从这些海量数据中高效、实时地获取能够为业务人员所用的有效信息。 柏睿数据智慧工厂解决方案通过将大语言模型与物联网技术相结合,赋能工厂智能运维场景,重塑数据追踪和分析流程,助力工业企业获得更深入的洞察和智能决策,提高生产质效、降低成本。 首先,采集工厂设备大数据,包括建立设备静态、动态统一的数据库以及设备管理全业务环节的日常业务数据库。 其次,建立“引发工况的可能问题”的样例库。分析不同类型设备出现的不同故障表现及原因并采取适当行为解决该故障,由此形成故障体系。 再次,通过建立专家知识库配置平台,将行业专家的知识整理后录入知识库,作为工厂故障诊断分析、优化运行的指导依据。 最终,一方面将知识库的内容向量化存储到向量数据库中,与LLM结合,输出应对故障和优化问题的、基于经验的回答;另一方面,使用积累的数据对LLM进行微调,使得系统在每次处理和分析数据的过程中都能够通过持续的数据库运算进行“学习”。
010-64700868 400-088-1960
品牌市场:brmarketing@boraydata.com
人才招聘:hr@boraydata.com
北京市朝阳区酒仙桥北路乙十号院

微信视频号

微信公众号
COPYRIGHT ©2014-2025 北京柏睿数据技术股份有限公司京ICP备16005192号隐私协议法律声明
 京公网安备 11010502043838号
京公网安备 11010502043838号


