发布时间:2024-07-31 | 阅读:

Elon Musk最近在Memphis超级集群中使用了RDMA网络结构,引起了全球范围内高度的热度和关注。Memphis超级集群是目前世界上最大的超级集群,集成了10万块H100 GPU,专门用于构建超级AI模型。Memphis超级集群不仅标志着AI基建底座的重大突破,也凸显了RDMA在未来技术发展中举足轻重的位置。
本文将深入探讨什么是RDMA,并结合柏睿数据在这一领域的最新突破,探讨RDMA在未来AI基建底座中的实际应用。

什么是RDMA?
RDMA支持未来AI基建底座
AI模型的训练需要处理海量的数据和复杂的计算,这对数据传输速度和延迟提出了极高的要求。传统的数据传输方式往往难以满足这一需求,而RDMA则通过直接内存访问提供了高效的数据传输途径。
Elon Musk在Memphis超级集群中使用RDMA网络结构,正是为了应对AI模型训练的这一挑战。通过RDMA,Memphis超级集群能够实现低延迟、高吞吐量的数据传输,大幅提升AI模型训练的效率。这不仅加快了AI模型的开发速度,也为更多的创新应用奠定了坚实的基础。

最近,柏睿数据的RDMA技术突破也为未来的AI基础设施提供了重要支持。通过将RDMA封装成Socket接口,使得开发人员可以使用熟悉的Socket编程模型,而无需直接处理RDMA的复杂性。这一创新不仅简化了RDMA的应用门槛,还提高了应用程序的可移植性和兼容性。在不同Payload Size、多线程情况下的测试结果显示,RDMA Socket显著提升了数据传输的速度和效率,为AI模型的快速迭代和优化提供了坚实保障。

借助RDMA技术,柏睿AI智算一体机已经实现类似英伟达GPUDirect技术在存储、网络、GPU之间的直接通信,突破了异构数据传输瓶颈,又大大降低了对CPU资源的占用。
RDMA+全内存分布式计算引擎
对于柏睿数据的全内存分布式计算引擎来说,其核心在于数据处理的速度和查询响应的效率。RDMA的引入无疑是一个革命性的进步,全内存分布式计算引擎可以大幅提升数据传输的效率,减少查询延迟。
通过RDMA Socket的创新,开发人员可以更轻松地利用RDMA的高效数据传输能力,推动数据库系统的进步。在测试环境中,柏睿数据展示了RDMA Socket在不同Payload Size、多线程情况下的卓越性能。测试结果表明,RDMA Socket在延迟和吞吐量方面均显著优于传统的Socket接口,时效提升约百倍,并且在某些情况下,性能接近于原生RDMA。这一成果表明,通过RDMA Socket,应用程序可以在不显著增加系统开销的情况下,大幅度提升性能。
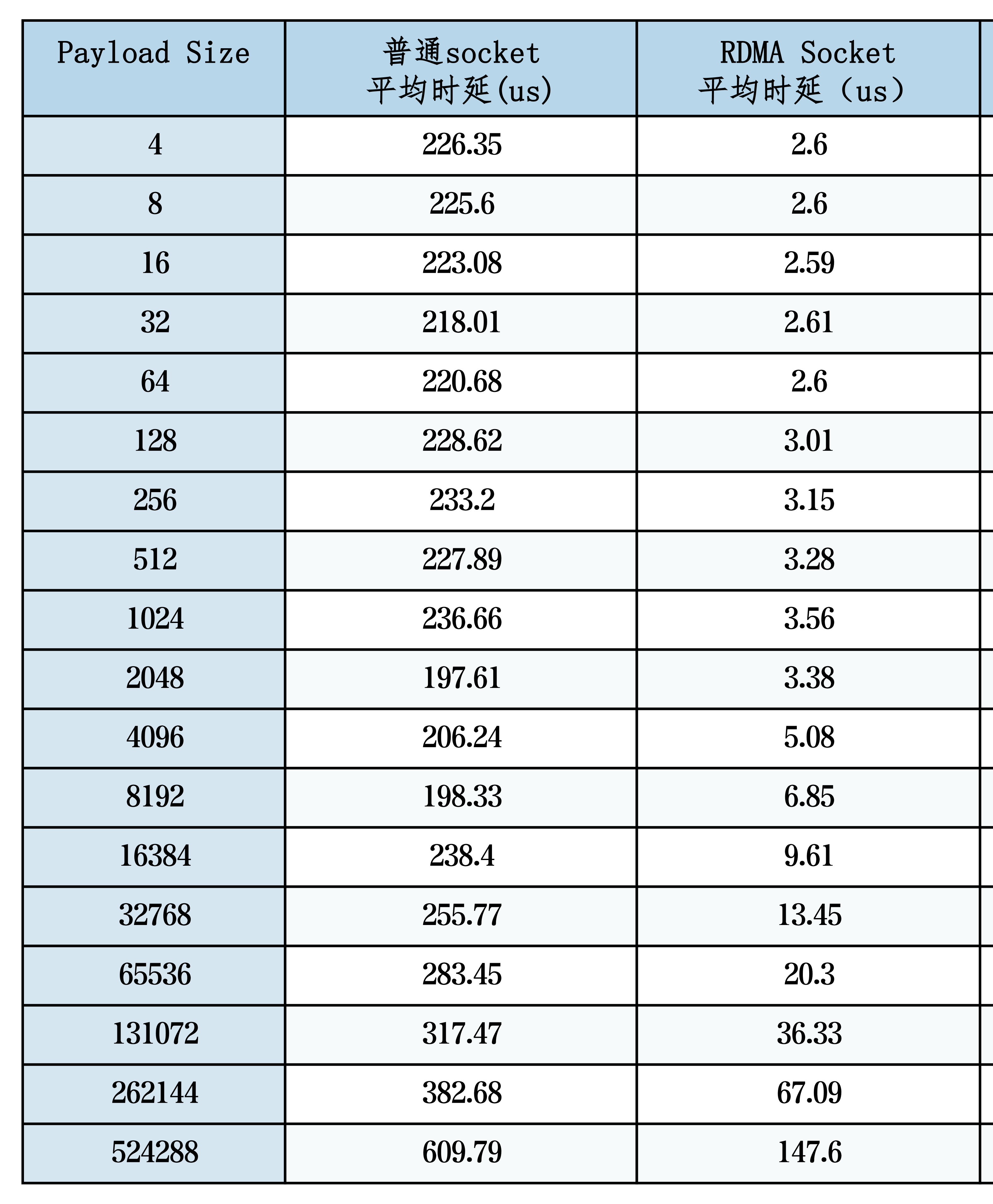
*测试数据来源于柏睿数据《RDMA Socket测试报告》

由于RDMA减少了CPU的直接参与,系统资源可以更集中地用于实际的数据处理和查询优化,从而提升数据库的整体效率。测试结果表明,RDMA Socket在不同Payload Size、多线程情况下的性能卓越,显著优于传统的Socket接口,并且在某些情况下,性能接近于原生RDMA。
010-64700868 400-088-1960
品牌市场:brmarketing@boraydata.com
人才招聘:hr@boraydata.com
北京市朝阳区酒仙桥北路乙十号院

微信视频号

微信公众号
COPYRIGHT ©2014-2025 北京柏睿数据技术股份有限公司京ICP备16005192号隐私协议法律声明
 京公网安备 11010502043838号
京公网安备 11010502043838号



